Matthieu Ballandonne、 Igor Cersosimo
文本分析方法如今已经愈发成熟,其在经济思想史研究领域的扎根也初露端倪。但大多数该领域学者心中仍有或多或少的困惑——一个很大程度上依赖于使用推理演绎和历史分析处理高度复杂的文本的领域,应当如何接纳这一基于数理统计的分析方法以实现自身更好的发展。作者使用文本分析工具对斯密的经典著作《国富论》、《道德情操论》展开分析。研究表明,文本分析工具能够在一定程度上提供可靠的主题词列表,还能够对特定主题进行检索。《道德情操论》相对《国富论》而言词汇更丰富、阅读难度更高,且话语风格上偏向于对话型,而《国富论》则偏向于独白型。作者的情感分析表明,斯密的语句在情感上是丰富多样的,但总体结果的解释仍存在一定的困难。同时,作者也看到了量化工具在该领域应用时的不足,但希望通过他们的努力,推动这一工具早日汇入思想史领域研究的主流。
一、引言
近年来,计量工具在经济思想史领域已经愈发流行。然而,在很大程度上,文本分析工具并没有得到足够的重视。在作者看来,这并不合理,因为这个领域的研究人员,平常最重要的工作就是对文本的处理。在作者看来,除去一些技术上的问题,我们对以下基本问题的困惑是这一现象的根源:1)经济思想史学者到底能用文本分析方法研究什么样的问题?2)考虑到文本的特殊性,文本分析方法到底能多大程度上适用?3)文本分析的结果和传统方法研究的结果又有什么异同?如何解释?所以,作者使用文本分析法对斯密经典著作《国富论》、《道德情操论》进行了主题、风格(词汇丰富度、阅读难度、话语风格)、情感方面的分析,揭示了这两本书的一些重要特点和区别,希望能够对这些问题做出回应。
二、文本预处理
在进行文本分析前,首先要对文本进行以下处理,将文本转化为更结构化的数据,从而能够使用成熟的量化工具。1)大小写转化(Case handling)。文本分析使用到的一些r函数需要用大写字母来检测文本的一些特征,例如地名、人名。2)分割与标记(Tokenization)。因为全文过于具体、量太大而没法进行任何有意义的文本计量,因而需要将句子拆分成离散的单词与符号,并形成“标记”(Tokens)和“类型”(Types)。Tokens即为含重复的全文所有出现过的分析元素(词汇,符号等),Types即为不包含重复的全文所有出现过的分析元素(词汇、符号等)。此外,语句中的连字符词汇(如self-command)将被拆分开再标记(self,command)。举个例子简要说明这个过程:Rose is a rose is a rose is a rose.这个句子中,tokens的数量是10,而types的数量是3(rose,is,a)3)词汇聚类(Stemming),就是将派生词转化为其词根(例如将thinking和thinker转化为think)。采用词汇聚类后就会大幅减小程序分析的难度和结果的复杂度。但在全文的分析中,因为涉及到情感分析,出于审慎的考虑,作者没有进行词汇聚类。4)词汇剔除(Stop words),在这一步中,剔除掉一些高频但无意义的词汇,例如“a”、“the”。经过如此处理后,得到一组重要的数据。

表1 两本著作中标记、类型、句子和页码的数量
三、主题分析
文本分析方法经常被用来检索主题和关键词,作者使用TF-IDF方法、Keyness方法和共现分析方法来实现这一目的。
3.1TF-IDF法和Keyness法
TF-IDF法(Term Frequency-Inverse Document Frequency),直译为词频-逆文档频率法,通常由目标文档词频和对照文库反词频相乘得来。Keyness法的计算方法与TF-IDF法有轻微不同,其通过计算目标文献和参考文献中特定词频率的χ2统计量得到一篇文献中的特征词汇。两种统计方法基于同一种原理来寻找特征词汇,即如果一个词汇在目标文档中出现频率很高,而其在同类型文档中出现频率很低,则该词汇就是目标文档的特征词汇,也更可能是作者想要讨论的主题。分析结果如表2所示。
表2中TMS代指《道德情操论》,WN代指《国富论》。从直观上,可以看出《道德情操论》的主题词大多属于情感类(joy、sorrow、emotions、love、anger)或道德类(virtue、conduct、judgments、approbation);《国富论》的主题词大多是经济概念(price、money、tax)。

表2 基于TF-IDF法和Keyness法的主题词
两种方法所得到的关键词通常是不同的。对于《道德情操论》来说,使用TF-IDF方法,最容易检测到“joy”、“sorrow”、“emotions”这样的单词。相反,通过Keyness方法则容易检测到人称代词、“sentiments”、“virtue”等。在《国富论》中,使用Keyness法则容易检测到“price”、“money”和“labour”等词。可以看出他们能在一定程度上互补,其结果的集合能够提供更加完整、可靠的关键词目录。
另一个重要的发现是,根据特征词法(keyness),常用的剔除词汇在《道德情操论》中被程序剔除(we、our、us、he、his、him、man、with),而在《国富论》中却没有被检测到。这是很反常的,因为在大多数文本中,剔除词通常是频繁出现的。事实上,两本书在人称代词使用上的不同,将向我们展示这两本书的一个重要差别,下文对此进行了进一步的讨论。
3.2 共现分析
前面的两种方法均是对单个词进行的分析,但实际上有些重要的主题词是两个词的搭配。但如果将其拆分开来进行分析,两个词的词频相对较低,均无法被算法检测出来。因而,可以通过共现分析来考虑这种情况。所谓共现分析,即分析两个词是否容易出现在同一个句子中,作者在文中使用一个φ系数来衡量之。两个词汇越容易同时出现,则他们的φ系数越接近1,反之则接近-1。
首先进行了词汇剔除,只保留在《道德情操论》中出现超过15次、在《国富论》中出现超过20次的词汇(最小阈值不同是因为两本书长度不同)。然后找出共现频率最高的词组,结果如图1所示。
在《道德情操论》中,程序检测出了一个众所周知的中心表达“impartial-spectator”,因而可以认为共现分析在一定程度上是有效的。此外,程序还检出了“self-command”、“amiable-respectable”等词。
还有一个有趣的发现是,斯密倾向于在同一个句子使用意义相反的词汇,例如:“right-wrong”、“pain-pleasure”、“approve-disapprove”、“beauty-deformity”、“merit-demerit”等。有理由认为,这一定程度上是为了文辞的修饰,也有可能是为了加强不同观点的对比。

图1 《道德情操论》中共现频率最高的50对词
在《国富论》中,程序检出了“butcher’s meat”这个众所周知的搭配短语。此外“silver-gold”、“spain-portugal”、“standing-army”、“answering-occasional-demands”、“forts-garrisons”、“latter-former”、“necessaries-life”、“east-indies-west”等搭配词也被程序检测到。
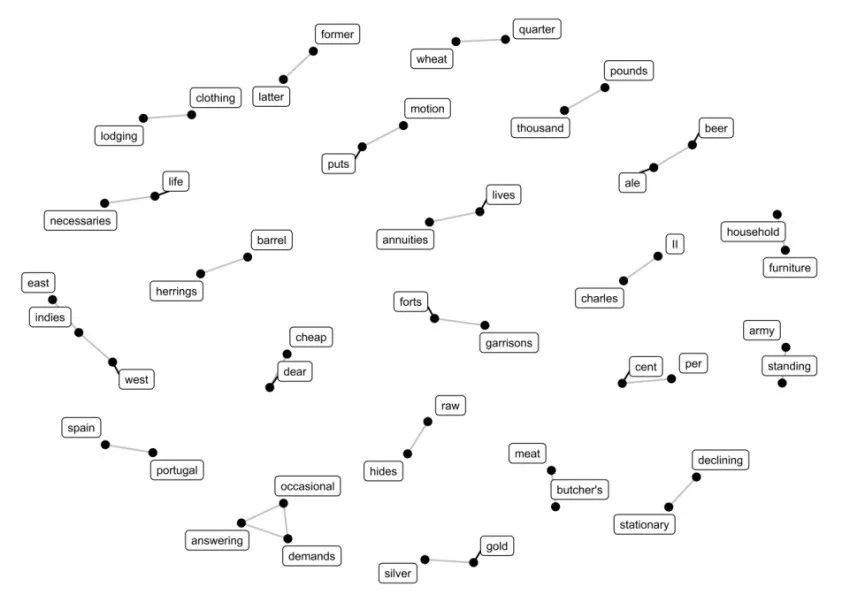
图2 《国富论》中的共现频率最高的50对词
共现分析还识别出了一些斯密惯用的组合,例如《道德情操论》中的“one-another”、“go-along”。而“former-latter”在斯密的两本著作中都被检出。这种表达就像人的DNA一般,可以当作作者的特征表达。
3.3 特定主题检索——斯密论战争
文本分析法能否对特定概念展开分析呢?本小节以“war”为例展示之。作者使用了Keyness方法,其中目标句子是包含“war”的句子,对照句子是不包含“war”的句子,从而找出在包含目标概念的句子中出现而其他句子中不常出现的概念,即与“war”相关联的特征概念。

图3 《道德情操论》中“war”相关单词和不相关单词的χ2值

图4 《国富论》中“war”相关单词和不相关单词的χ2值
首先可以从词频分析中观察到,两本著作中“war”出现的频率是不同的,在《国富论》中“war”出现的概率是6.17/10000,而在《道德情操论》中则是2.29/10000。因而,有理由认为斯密倾向于在《国富论》中讨论战争。
从图3中可以观察得出:在《道德情操论》中,斯密在讨论战争时倾向于使用“enemies”、“faction”、“hazards”、“hardships”、“tumult”等词,后三者可能暗示,斯密倾向于在一个矛盾激烈的语境中使用“war”,从这样的结果看,《道德情操论》中与“war”相关联的词汇并不是那么地“道德”。作者同时也警告我们,在这本著作中,“war”的出现频率并不高,这可能会增加结果的偶然性。
从图4中可以得出:在《国富论》中,“debt”、“funding”、“contracted”、“peace”等词通常与“war”相关联,这表明,斯密更乐意讨论战争的经济代价。而“price”、“labour”和“market”等主题词的出现表明,斯密倾向于在不含“war”的句子中讨论这些话题。
四、
文献风格分析
文章的第三部分展示了文本分析法在词汇丰富度分析、阅读难度分析及话语风格分析中的作用。
4.1词汇丰富度
一般来说,度量词汇丰富度有两个方法:1)TTR(Types Tokens Ratio)即Types数量与Tokens数量的比值。2)Hapax legomenon,即文献中只出现过一次的词汇数量占比。但这两种方法都存在一定的缺陷,特别是当文献长度较长时,由于受到其作者词汇边界的限制,两个指标的大小几乎只和文献长度相关。因而,作者使用了一种改进型的TTR法——MATTR法(moving-average type token ratio),即将取样区间固定(文章中为500个词),计算连续的每个取样区间内的TTR数值再求均值,分析结果如图5。

图5 两本经典著作中的MATTR值
根据分析的数值结果可以直观地看出,在一定程度上《道德情操论》的词汇丰富程度高于《国富论》。这可能与三个因素有关,其一是讨论的话题:相比于财富增长的话题,道德哲学所需要用到的词汇可能更丰富一些;其二是目标受众,18世纪的哲学家可能比同时代的商人、政治家掌握更多的词汇;第三个解释与作者本身有关,一般人经验越丰富、年龄越大,越喜欢简洁、直接的表述方式。例如,斯密著作的研究人员温斯坦曾说“随着年龄的增长,斯密的写作风格变得更有效率,更少华丽。”这也与作者的研究结果不谋而合。4.2阅读难度在研究了斯密的《修辞学与文学讲稿》之后,布朗写到“(斯密的著作)尽管某些地方的语言比较微妙、难懂,但其文章整体上读起来显得轻松优雅,并不晦涩”。可斯密的书真的容易读吗?两大著作在这方面有什么区别吗?为了回答这些问题,作者计算了两本书的阅读难度指标。阅读难度的两个常用的衡量指标是Flesch阅读轻松度评分和Flesch-Kincaid年级水平评分(下文简称F-K指标)。尽管表述不同,但这两种衡量标准都基于这样一种观点,即句子较长(每句的单词数)和单词较长(每个单词的音节数)的文本相对更难以阅读。也就是说,阅读难度评分是基于句子和单词的结构,而不是他们的含义。

可以看出两个指标的区别主要在于句子长度和单词音节数的权重不同,F-K指标更偏向于句子长度。作者采用了F-K指标进行分析,因为它对应着美国的学校系统,分析结果如图6。

图6 两本著作中的F-K指标可以看出,这两本书一般都需要在14年级到20年级之间的教育水平才能阅读(14年级约相当于大学2年级)。因而,根据这个指标,斯密的书可以被认为是难读的。从定量角度看,这与布朗对斯密著作的描述相矛盾。从两本书的对比来看,《道德情操论》的阅读难度要高于《国富论》,那么怎样去解读这样的结果?在作者看来,这可能是缘于目标群体的差别,“有理由认为,18世纪的哲学家的教育水平高于同时代的商人”。下文更进一步分别按照句子长度和音节数量对这两本著作进行了分析,展示了两本著作更细微的区别,如图7。

图7 两本著作单句平均词数和单词平均音节数的盒型图
从句子长度上来看,两本著作几乎没有明显区别,都是每句34-35个词。但在音节长度上,可以发现《道德情操论》要明显比《国富论》要长,前者在1.58个音节之上的单词占到50%左右,而《国富论》在1.58个音节以上的单词只有其总数的25%。所以总的来说,从句子长度上两本书几乎没有差别,但从单词音节数上考虑,《道德情操论》确实比《国富论》难读一些。4.3话语风格前文主题分析已经揭示:与《国富论》相比,《道德情操论》的特点之一是频繁使用某些人称代词:“we”、“our”、“he”等,这可能揭示了一个两本书话语风格上一个重要的差异:《道德情操论》是对话型的,而《国富论》是独白型的。为了更进一步分析,作者整理了所有人称代词的相对词频,如图8。结果是清晰而明显的,斯密在《道德情操论》中频繁地使用了“I”、“you”、“he”、“him”、“we”等人称代词,而在《国富论》中则与之相反。这也与采用定性方法研究等学者的结论不谋而合,布朗在其著作《亚当·斯密的论述:商业、正统与良心》(Adam Smith's Discourse: Canonicity, Commerce and Conscience)中写道“《道德情操论》的开放性和不确定性......使其作品在风格上成为一种多元的对话形式。相比之下,《国富论》在很大程度上被一种单一的声音所笼罩,论述的更多是确定性和规则”。

图8 两本著作中人称代词的相对词频
作者也反复强调该结论的适用范围,即一个独白型的文本并不意味着整篇文章只有一个人的观点,而是意味着其他观点都用以论证主要的观点,“独白型和对话型文本的差别不在于出现观点的数量,而在于这些观点交互的方式”。正如布朗所说“《国富论》的观点其实是很多元化的,但其与《道德情操论》的一个重要的差别是,那些其他的观点无法对主要观点构成挑战”。同时,作者的研究结果也不支持“《国富论》是一个纯粹的独白性、授课性著作”的观点,因为即使那些人称代词的词频较低,也都自始至终存在于斯密的行文当中。
五、文献情感分析
文章最后一部分——情感分析,或许也是全文争议最大的部分,作者试着通过一种“查字典”的方法确定全文的行文情感(积极或消极),这种想法单是从直觉上就很容易遭到读者的质疑。在数理统计学上,如果对一个随机变量进行多次独立重复实验,那么结果的分布便存在一定的规律性,在依概率预测的基础上,还可以进行假设检验等验证预测的可靠性。但在语言学上,是否存在类似的“大数定律”,即可以认为特定单词可以一定程度上和特定情感相联系呢?换言之,这样的“字典”是否存在呢?并且,这种方法的结果严重依赖于采用的“字典”,那么如何说明其“字典”的可靠性呢?
且让我们暂先忽略这些质疑,聚焦于作者的工作。作者采用的字典是R语言(版本2.9.0)的一个工具包——sentimentr的拓展版本,其内核被称为Jocker-Rinker极性表(Jockers and Rinker’s polarity table),但因为字典原本是基于美式英语开发的,因而作者将其不包含的一些英式英语加入其内,对其进行拓展。
字典法的原理是简单而明了的。首先,整句被离散为单个的词汇,然后程序在字典内挨个查询这些离散词汇的情感值再加总,即可得每句话的情感值。字典中,乐观、积极的词汇的情感值为正数,而悲伤、消沉的词汇的情感值为负数,中性词的情感值则为0,分析结果如图9。

图9 两本著作情感分析散点图与盒型图
从左侧图中可以看出,可以直观看到的是,线周围的散点分布比较杂乱,这意味着情感分析的结果波动程度较大。对结果进行平滑处理可以得到两条情感曲线,曲线上数值均为接近0的正值。右侧的箱线图中,许多句子的情感得分落在了箱线图的上下界之外,更直观地表现出数据波动的幅度之大。从定性分析的角度看亦是如此,即两本著作中充满情感的句子都是非常丰富的。因而,“很难从定量结果中得出本书总体上的有力结论”。
作者认为他们的工作能带来两个重要的启示:
其一,情感分析可能不适用于长文本,而更适用于对短篇的、当代的或情感起到一定作用的文本(如小说)进行分析。斯密的书很难读,句子长、音节多,这可能会让情感分析方法失效。
其二,所使用的字典至关重要。虽然已经对所使用的字典进行了拓展,使其可以被用于英式英语的分析,但仍有一个重要问题未解决——字典的词汇并不是基于经济学或道德哲学。那么这就会导致一来许多专业词汇没有被纳入其中,二来许多专业词汇的情感评分不对。例如:在《国富论》中常常讨论的“金”、“银”、“财富”在经济学中都是中性的,但在词典中却被确定为偏积极的。反之“税负”、“劳动”等经济学中的中性词汇则被确定为偏消极的。
因而,总的来说,“即使我们已经尽最大努力使这一正流行的方法适用于经济历史文本的分析,但结果并不容易解释清楚”。因而,作者也建议我们,“目前应当十分谨慎地将情感分析方法应用于经济历史文本的分析”。
六、结语
在经济历史文献分析领域,文本分析法确实是一个比较新的方法。作者向我们展示了其在主题分析、文本风格分析和情感分析上的潜力。
在主题分析上,TF-IDF法和Keyness法可以提供简洁、直接的主题词,还可以通过对比找出两个文献之间的区别。共现分析可以找出那些作者惯用的搭配、洞察某些主题词之间的联系。文本分析法还可以用于对特定概念进行检索,作者检索了斯密关于“战争”的论述;作者也看到了主题检索方法的局限性,事实上,它们的有效性一定程度上取决于一些技术上的设置,如最小阈值、参考文献库的选择等。
在文本风格分析上,作者对两本经典文献进行了阅读难度、词汇丰富度和话语风格的分析,阅读难度上,有理由认为两本书都是难读的;词汇丰富度上,《道德情操论》在一定程度上高于《国富论》,作者认为可以从话题、受众和斯密本人来解释这个现象;话语风格上,《国富论》偏向于独白型、授课型,《道德情操论》则偏向于对话型。
作者运用字典法对两个文献进行了情感分析,结果显示,不同句子的情感值波动较大,而总量则为接近于0的正值。然而,为作者的结果找到合理的经济学解释似乎并不容易,因而仍需要进一步的研究工作。作者在这一部分的最后,努力告诫我们,由于经济历史文献本身的复杂性,最好谨慎地使用情感分析工具。
作者在文章的最后,努力提醒我们,不要忽略定量分析的局限。正如葛雷默所说“语言的复杂性意味着自动的分析方法永远不会取代对文本的仔细阅读···这些方法···最好被认为是用以辅助我们深入理解文本的工具”。
原文信息:
Ballandonne, M., &Cersosimo, I. (2023). Towards a “text as data” approach in the history of economics: an application to adam smith’s classics.
, 45(1), 27-49.

